
October 14, 2024

Today we’re releasing our most capable and conversational voice model that can speak in 30+ languages using any voice or accent, with industry leading speed and accuracy. We’re also releasing 50+ new conversational AI voices across languages.
Our mission is to make voice AI accessible, personal and capable for all. Part of that mission is to advance the current state of interactive voice technology in conversational AI and elevate user experience.
When you’re building real time applications using TTS, a few things really matter – latency, reliability, quality and naturalness of speech. While we’ve been leading on latency and naturalness of speech with our previous generation models, Play 3.0 mini makes significant improvements to reliability and audio quality while still being the fastest and most conversational voice model.
Play3.0 mini is the first in a series of efficient multi-lingual AI text-to-speech models we plan to release over the coming months. Our goal is to make the models smaller and cost-efficient so they can be run on devices and at scale.
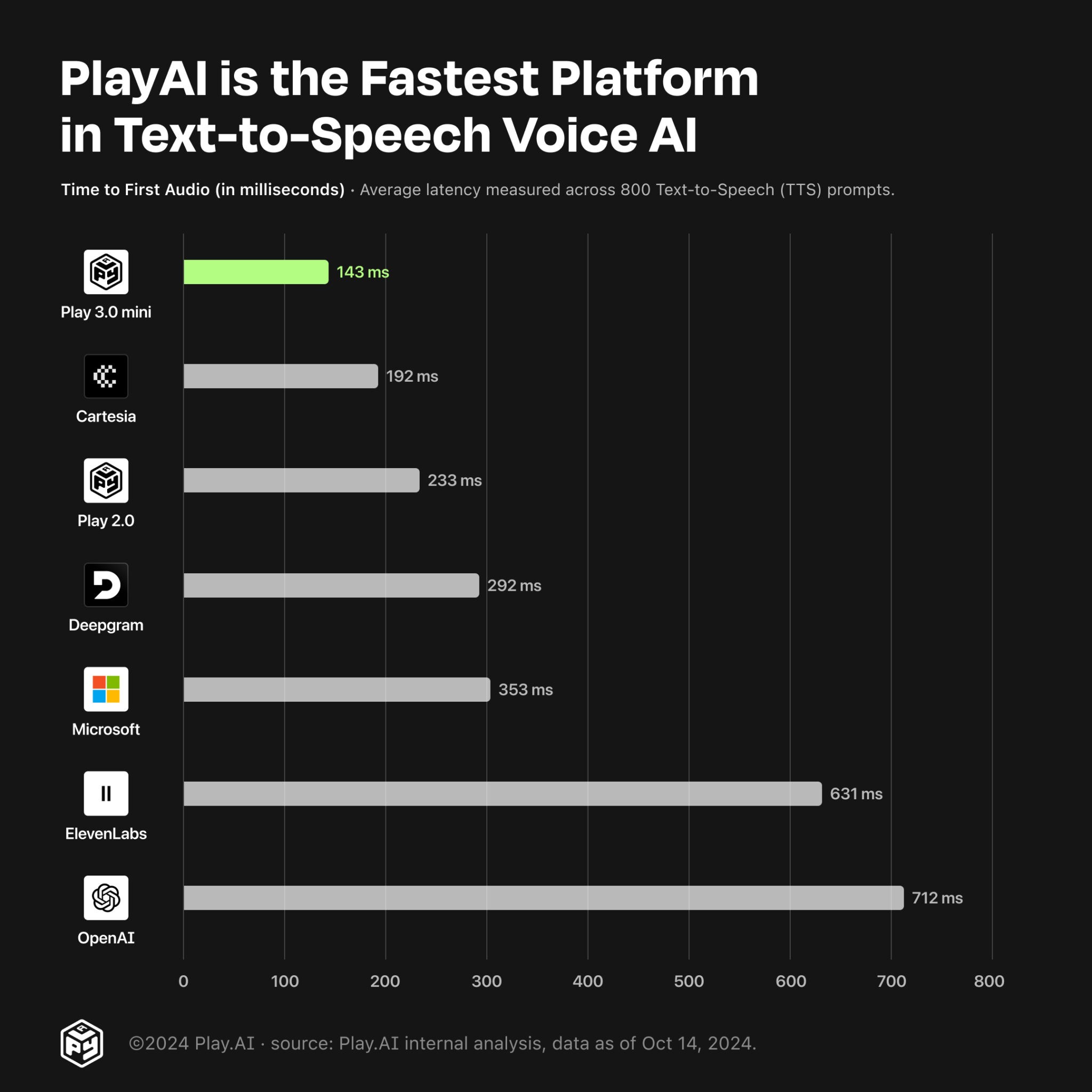
Play 3.0 mini is our fastest, most conversational speech model yet
3.0 mini achieves a mean latency of 143 milliseconds for TTFB, making it our fastest AI Text to Speech model. It supports text-in streaming from LLMs and audio-out streaming, and can be used via our HTTP REST API, websockets API or SDKs. 3.0 mini is also more efficient than Play 2.0, and runs inference 28% faster.
Play 3.0 mini supports 30+ languages across any voice
Play 3.0 mini now supports more than 30+ languages, many with multiple male and female voice options out of the box. Our English, Japanese, Hindi, Arabic, Spanish, Italian, German, French, and Portuguese voices are available now for production use cases, and are available through our API and on our playground. Additionally, Afrikaans, Bulgarian, Croatian, Czech, Hebrew, Hungarian, Indonesian, Malay, Mandarin, Polish, Serbian, Swedish, Tagalog, Thai, Turkish, Ukrainian, Urdu, and Xhosa are available for testing.
Play 3.0 mini is more accurate
Our goal with Play 3.0 mini was to build the best TTS model for conversational AI. To achieve this, the model had to outperform competitor models in latency and accuracy while generating speech in the most conversational tone.
LLMs hallucinate and voice LLMs are no different. Hallucinations in voice LLMs can be in the form of extra or missed words or numbers in the output audio not part of the input text. Sometimes they can just be random sounds in the audio. This makes it difficult to use generative voice models reliably.
Here are some challenging text prompts that most TTS models struggle to get right –
"Okay, so your flight UA2390 from San Francisco to Las Vegas on November 3rd is confirmed. And, your record locator is FX239A.”
"Now, when people RSVP, they can call the event coordinator at 555 342 1234, but if they need more details, they can also call the backup number, which is 416 789 0123.”
"Alright, so I’ve successfully processed your order and I’d like to confirm your product ID. So it is C as in Charlie, 321, I as in India, 786, A as in Alpha, 980, X as in X-ray 535.“
3.0 mini was finetuned specifically on a diverse dataset of alpha-numeric phrases to make it reliable for critical use cases where important information such as phone numbers, passport numbers, dates, currencies, etc. can’t be misread.
Play 3.0 mini reads alphanumeric sequences more naturally
We’ve trained the model to read numbers and acronyms just like humans do. The model adjusts its pace and slows down any alpha-numeric characters. Phone numbers for instance are read out with more natural pacing, and similarly all acronyms and abbreviations. This makes the overall conversational experience more natural.
“Alrighty then, let’s troubleshoot your laptop issue. So first, let’s confirm your device’s ID so we’re on the same page. The I D is 894-d94-774-496-438-9b0.“
Play 3.0 mini achieves the best voice similarity for voice cloning
When cloning voices, close often isn’t good enough. Play 3.0 voice cloning achieves state-of-the-art performance when cloning voices, ensuring accurate reproduction of accent, tone, and inflection of cloned voices. In benchmarking using a popular open source embedding model, we lead competitor models by a wide margin for similarity to the original voice. Try it for yourself by cloning your own voice, and talking to yourself on https://play.ai
Websockets API Support
3.0 mini’s API now supports websockets, which significantly reduces the overhead of opening and closing HTTP connections, and makes it easier than ever to enable text-in streaming from LLMs or other sources.
Play 3.0 mini is a cost efficient model
We’re happy to announce reduced pricing for our higher volume Startup and Growth tiers, and have now introduced a new Pro tier at $49 a month for businesses with more modest requirements. Check out our new pricing table here.
We look forward to seeing what you build with us! If you’ve custom, high volume requirements, feel free to contact our sales team. ⬢